Previously, I wrote about the three frameworks we use for data analysis at Khan Academy. Since then, we have automated the export of production data into BigQuery and are regularly using it to perform analysis. We have all but deprecated our Hive pipeline and things are going great! Here, I’ll go over what has gone well, what concerns we have, and how we set everything up.
Benefits
The biggest benefits are the easy integration with other Google services, and a great querying interface. We also enjoy using the BigQuery API to pull data into various python or R analysis scripts.
Getting our data from the AppEngine datastore into BigQuery was primarily done by copying some code examples that Google has published, and hooking them up with some extra functionality like robust error checking, scheduling, and custom transformation. It was not trivial to get things working perfectly, but it was much easier than setting Hive up. Since all of the processing happens with Google libraries, it is easy to manage our data warehousing jobs alongside the management dashboards that we use for the rest of the website.
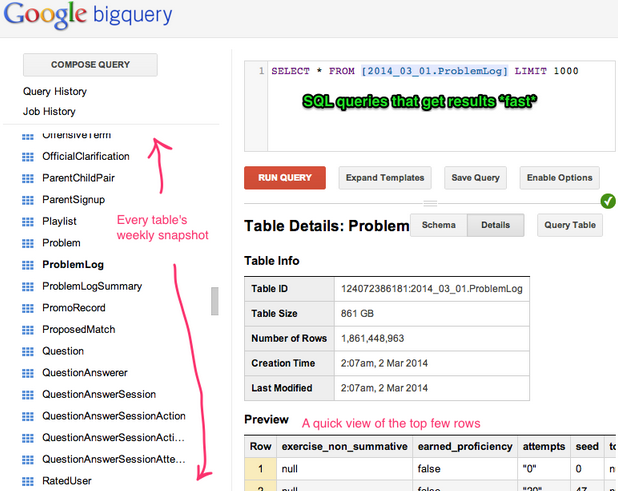
The querying interface was what got us excited about BigQuery when we were trying to decide if we could replace our Hive pipeline. The biggest benefit is the speed at which results can be returned, particularly over small datasets. Our Hive setup took a minimum of 60 seconds to spin up a distributed query, even if the dataset was small. This is maddening when you’re debugging a new query. BigQuery is blazingly fast, right out of the box. Here’s a query that sums a column over 1,939,499,861 rows in 1.6 seconds, and displays the result in your browser.
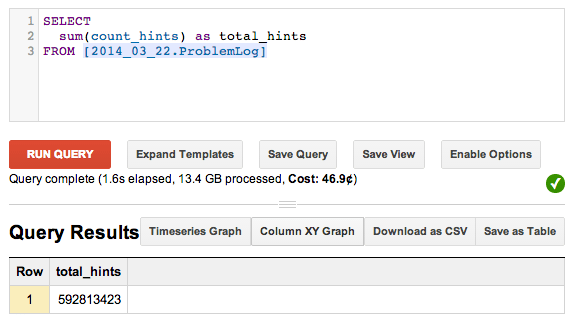
The browser-based querying interface is friendly enough that we were able to train people across the company to perform their own queries. Jace led a workshop to teach everyone the basics of SQL, and since then we have seen increased adoption of BigQuery analysis across the company. The “business people” love the power of their new skill, and the data science team is able to more effectively deliver insight. That may mean helping someone debug a query they’re working on, or writing a query that they can run and tweak as they see fit.

Concerns
The concerns we have are cost and flexibility. I feel like I should mention them, but, honestly, they pale in comparison to the benefits.
I have not done a deep comparative cost analysis, but it is clear that our Google bill has gone up significantly since loading up BigQuery with our production data. Part of this is a function of increased usage because it is simply more useable. We are working on revamping our A/B testing framework to log events into BigQuery for easy analysis, and cost has been a factor we’ve kept in mind while designing the system.
BigQuery’s SQL implementation is powerful, but omits many of the advanced features found in HiveQL. Native JSON processing and user-defined functions are two that we miss the most. BigQuery also complains about large JOIN or GROUP BY operations. Adding the EACH keyword in these cases often solves the problem. When it doesn’t, your only recourse is to do some manual segmentation into smaller tables and try again. The lack of flexibility is Google’s way of “saving you from yourself” by only letting you do things that will perform well at scale. This is usually helpful, but there are some scenarios where “getting under the hood” would be useful.
**UPDATE**: As I was writing this post, Google announced both a decrease in cost and the addition of native JSON processing.
How we set it up
Our BigQuery data warehousing pipeline consists of three stages:
- Backing up production data onto Google Cloud Storage
- Importing raw data from Cloud Storage to BigQuery
- Importing transformed data from Cloud Storage to BigQuery
- Read raw data from Cloud Storage
- Write transformed JSON data back to Cloud Storage
- Import transformed JSON data from Cloud Storage to BigQuery
This process runs every Friday evening, giving us a fresh snapshot of the entire production datastore ready for queries when we arrive Monday morning.
We use Google’s scheduled backups to serialize our datastore entities into files on Google Cloud Storage. We created a small wrapper around the `/_ah/datastore_admin/backup.create` API to start several batches of backups.
A cron job runs every 5 minutes to detect when the backups have made it onto Google Cloud Storage. When a new backup is ready to be loaded into BigQuery we use the BigQuery Jobs API to kick off an ingestion job, specifying DATASTORE_BACKUP as the sourceFormat.
After the load job finishes, BigQuery will have an almost identical copy of the datastore ready for super-fast queries.
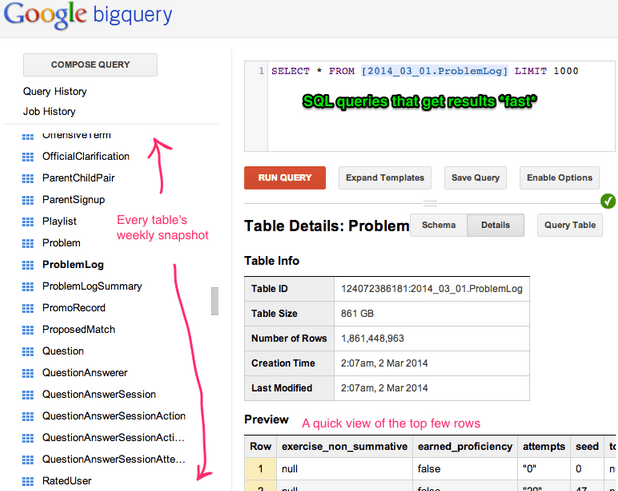
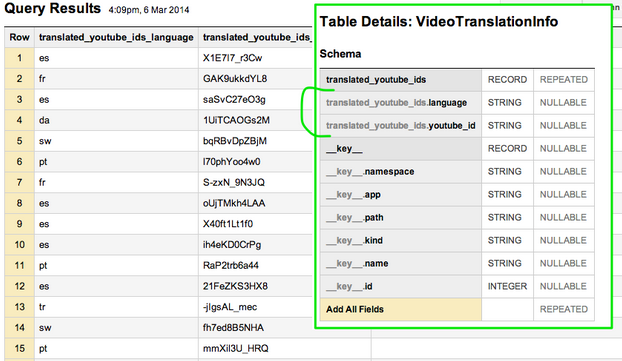
The automatic deserialization of the DATASTORE_BACKUP format works well for most properties, but properties that contain more complex data are ignored. For example, this model basically winds up empty in BigQuery. Each entity’s key is serialized, but everything interesting about this model is stored in the JsonProperty.
class VideoTranslationInfo(ndb.Model):
"""Mapping YouTube ID -> dict of YouTube IDs by language."""
translated_youtube_ids = ndb.JsonProperty()
We need a layer to transform the datastore format into something that BigQuery can understand. Google has a great codelab describing exactly this process. Google’s implementation uses a DatastoreInputReader to map over the datastore entities directly. We found that mapreducing over the backup files on Google Cloud Storage was just as easy and guarantees that the raw and transformed datasets are consistent. Plus, there is no danger of causing performance problems for users interacting with the production datastore. Our implementation uses JSON instead of CSV because it allows for repeated records. We made the system pluggable so developers could easily add new custom transformations to any entity with complex properties.
Running the VideoTranslationInfo through its corresponding transformer results in a much more useful schema: 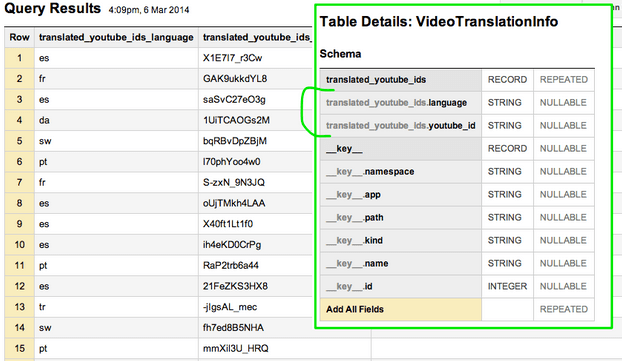
Daily request log export
We also export our web request logs into BigQuery. This is pretty easy to automate by deploying the log2bq project from Google. This is great because it allows “grepping” over the server logs with tremendously parallelized SQL.
Next stop: dashboards
Now that we have a wealth of data in BigQuery, I want to try building a web dashboard to visualize some of the most interesting results.
Have you used BigQuery? Do you have any success stories or complaints?
Props to Chris Klaiber, Benjamin Haley, Colin Fuller, and Jace Kohlmeier for making all of this possible!



 You can get the gist of how I got this working here. The main points are:
You can get the gist of how I got this working here. The main points are: