
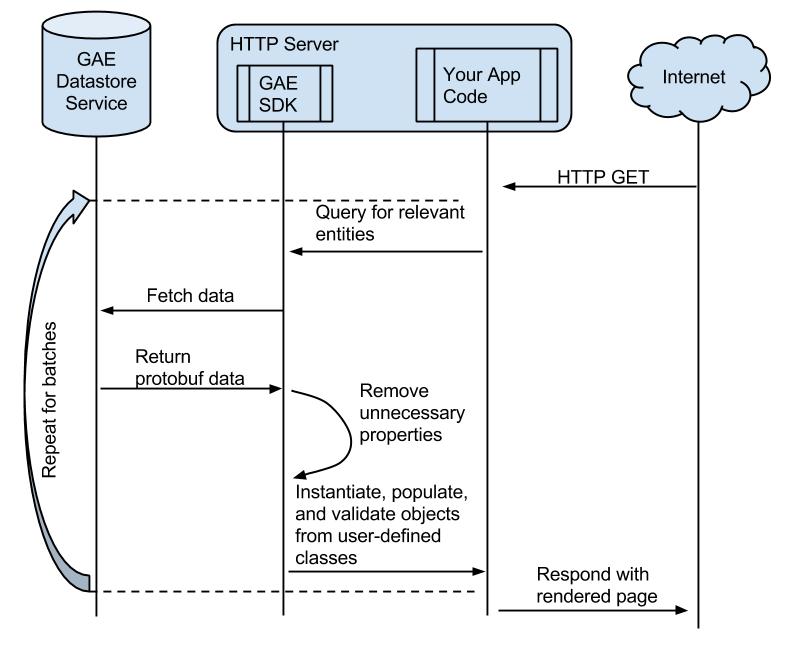
Like most frameworks these days, the Google Appengine (henceforth, GAE) SDK provides an API for reading and writing objects derived from your classes to the datastore. This saves you the boring work of validating raw data returned from the datastore and repackaging it into an easy-to-use object. In particular, GAE uses protocol buffers to transmit raw data from the store to the frontend machine that needs it. The SDK is then responsible for decoding this format and returning a clean object to your code.

This utility is great, but sometimes it does a bit more work than you would like. I found one query that was fetching 50 entities, each with over 60 properties. Using our profiling tool, I discovered that fully 50% of the time spent fetching these entities was during the protobuf-to-python-object decoding phase. This means that the CPU on the frontend server was a bottleneck in these datastore reads!

The problem was that the GAE SDK was deserializing all 60 of the properties from protobuf format, even though the code in question only required 15. The best way to solve this problem is with projection queries provided by the GAE SDK, which reduces both the download time and the objectification. But, each projection query requires its own perfect index. I wanted something with a little less overhead.
Using the magic of monkey patching (run within appengine_config.py), I modified the pb_to_entity function (which exists inside the GAE SDK) to drop unnecessary properties before performing the protobuf-to-python-object translation. This is much like the scenario where a new property is added to a Model. Entities that have not been written since the new property was introduced will return a protobuf that excludes the newly introduced property. With this change, the 2.9 seconds spent decoding was reduced to 900 milliseconds, a 3x improvement!
 You can get the gist of how I got this working here. The main points are:
You can get the gist of how I got this working here. The main points are:
- appengine_config.py monkey patches the relevant functions inside the GAE SDK so that my function runs instead.
- A context manager sets a global, thread-local variable with the names of the properties that we care about. The custom function only operates when this global variable is set.
- This means you should query against exactly 1 Model within the context.
- The __getattribute__ function is monkey-patched to provide access safety for projected objects. When you try to access an excluded property from an object that was created during protobuf projection, an exception is raised. This is a feature that “official” projection queries do not offer.
- Various put() functions are monkey-patched to disallow putting a projected entity. This provides parity with “official” projection queries.
Now that this code has been written, I will be on the hunt for more queries that might benefit from its use. If you use this code in your application, I would love to hear about it!

I logged this feature request in the GAE issue tracker: https://code.google.com/p/googleappengine/issues/detail?id=11518 If you’re interested in seeing this functionality supported in the SDK directly, feel free to star it!
LikeLike
Looks interesting – definitely going to try this and see how it affects performance.
I presume the missing classes are from: https://github.com/cosmic-api/cosmic.py/blob/master/cosmic/globals.py right?
e.g. ThreadLocalDict
LikeLike
Oops, I forgot to add those classes in. I updated the gist with thread_util.py which includes those classes. Let me know if you have any other problems or if it works out well, cheers!
LikeLike
Thanks, it seems to work (just a few import statements and I removed the threading test / dependency).
The only issue I had was that NDB appeared to put the partial model back into memcache which then affected subsequent reads.
I need to look into it more to say for sure – it could well be something I did wrong but restarting the app and requesting pages that resulted in a different model loading order would generate or skip the condition.
I’ll let you know when I get chance to run through it in more detail.
LikeLike
Ah, yes, that makes sense. We completely disable NDB’s use of memcache (via our @db_util.disable_ndb_memcache decorator).
The context cache (which stores the entities in the memory of the server which initially fired the datastore get) will still suffer this problem, though. I hit that problem in the test cases (which is why I added use_cache=False), but theoretically this could happen in the wild. I should fix that.
LikeLike
Unfortunately I found your blog post after I re-discovered the same performance issue. In our case, we used the db library, which is worse at this than ndb. Even worse, we used a db.Expando which is about 2X slower than an db.Model. Still: I wish I had searched for the right keywords and found this first! It would have saved me a bunch of time. If anyone is curious about a similar but slightly different approach, see my story: http://www.evanjones.ca/app-engine-db-serialization.html
LikeLike