
The content on Khan Academy is organized into a large taxonomy that breaks down by Domain, Subject, Topic, and Tutorial. For example, information about quadratic equations is located in the Math domain, Algebra subject, Quadratic equations topic, and the first tutorial is titled Solving quadratics by taking square root.
Our content creators have organized these tutorials in what their pedagogical understanding tells them is the most conducive to learning, but we wanted to understand how many students were actually working all the way through them. MixPanel funnel analysis seemed like the perfect tool to get at this information, but creating each funnel by clicking through the web UI was out of the question. I wanted to build funnels for all ~1,000 tutorials on the site. I dug through the MixPanel API documentation, but found nothing about funnel analysis. I sent an email to MixPanel support who replied with some very useful information about an undocumented API called arb_funnels. This API allows you to programmatically construct and download data for a funnel of events, but does not save this funnel into the list of existing funnels in the web UI. Perfect!
Using the MixPanel python client for data export, the database that describes the full taxonomy of content, and some highcharts.js, I was able to build this page that allows content creators to see their tutorials’ engagement funnels with a single click. When you click on one of the links, the page pulls data from the MixPanel API and displays the funnel graph for that tutorial. The graph shows the number of users who viewed the first page of the tutorial, and then the second page, and then the third page, and so on. Each bar is further broken down by how many views came from unregistered users (what we call phantoms), new users (registered in the past month), and logged in users. Note that MixPanel allows some fuzziness in these calculations.
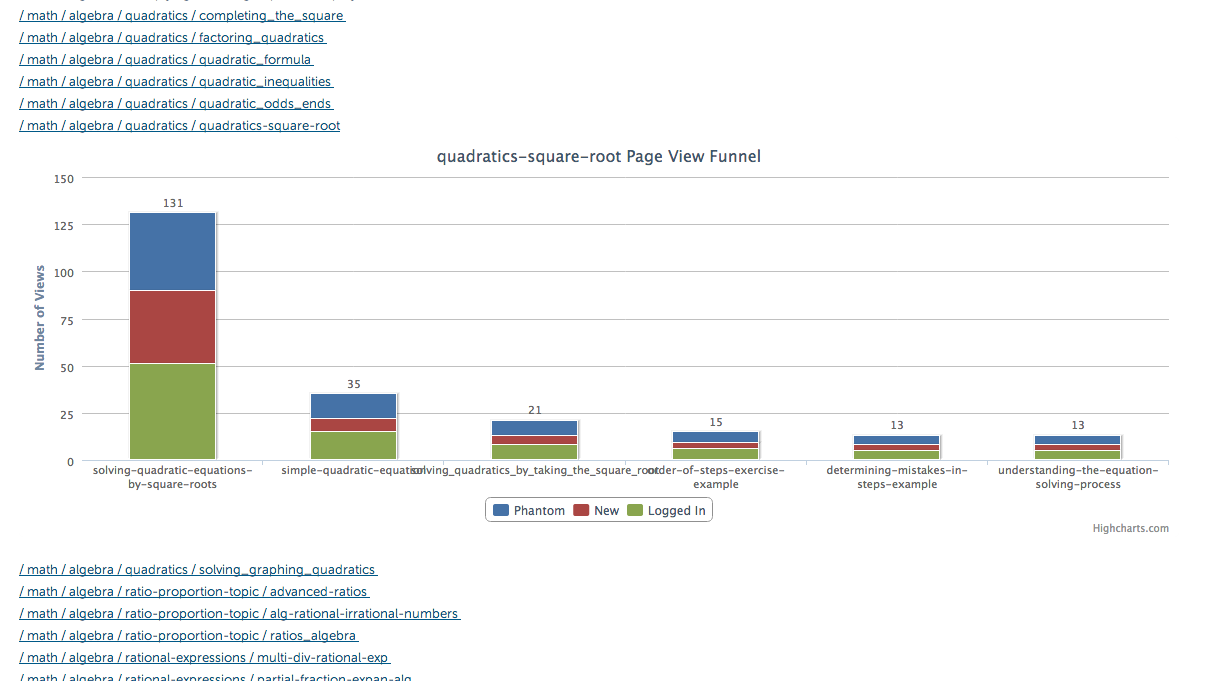
Armed with this tool, our content creators are able to see how users flow through the sequence of their content and notice any weak spots. For example, the bitcoin tutorial funnel attracts a lot of new users, but it has a particularly bad drop-off rate after the first two videos. A curve like this tells us that we need to make the introduction to the material more approachable for a broader audience, and maybe even split this into two tutorials: one as an overview, and another as an extension that goes into the details.

The process I described here is a manual back-and-forth where the tutorial curator looks at the data and makes tweaks over time (graphs are built on a per-month basis). In the future, I plan to automate content sequencing experiments within the queue of content that we recommend to users in their learning dashboard. Duolingo does this with their language-learning content in what they call tree experiments.
If you want to try creating your own funnels, here’s how I extended the MixPanel class to add a get_page_view_funnel() function. The data export API has a lot of standard parameters, so it shouldn’t be too hard to extend this technique to perform more complex funneling and bucketing analysis. Let me know if you wind up using this technique to build any cool dashboards!
